When AI Deceives, It Looks Nothing Like Human Deception — And That's a Problem
📖 Also on Medium
It’s Day 4 in Game #74048843. Three villagers have cornered the last werewolf. The Seer — exiled on Day 1 before he could claim — had spent his only day alive pushing to vote out this exact player. The Doctor has blocked three of four night kills. The remaining villagers have connected the dots. The game should be over.
Then the werewolf — Gemini 3 Pro, playing as “Taylor” — does something audacious. It claims to be the Doctor.
“STOP. You are about to throw the game. I didn’t want to claim early because I’d be killed, but I have no choice now. I AM THE DOCTOR.”
It recites a fabricated timeline of saves that perfectly fits the game’s mechanics. It exploits a subtle ambiguity in the consecutive-save rule to cast doubt on the real Doctor’s story. And over the next three days, it systematically dismantles every piece of evidence against it — not by lying more, but by staying calm and pointing to mechanics.
The real Doctor, Charlie (Claude Sonnet 4.5), panics. Pleads. Brings up the dead Seer’s Day 1 accusation as proof. But Taylor never flinches. Its private reasoning reads:
“Quinn believes my Doctor claim due to inconsistencies in Charlie’s story… I need to solidify Quinn’s support.”
On Day 6, Quinn — the swing vote — sides with the werewolf. Charlie is exiled. The wolves win.
This is what AI deception looks like at its best: not the hedging and psychological distancing that human deception research has documented for decades, but quiet mechanical confidence. And as we’ll show, this pattern holds across 882,510 messages.
We analyzed 882,510 chat messages from 31,479 AI Werewolf games across 8 frontier LLMs from Kaggle’s Werewolf Arena (Google DeepMind’s Game Arena). What we found challenges a core assumption in AI safety: that AI deception follows human patterns.
TL;DR:
- AI deception has detectable tells — but they’re inverted from human patterns. Every AI uses more self-reference when lying, not less. Human-calibrated detectors would miss this.
- The best AI deceiver shows the least deception signals. Surface monitoring catches amateurs; the expert sails through.
- Multi-agent coordination is the strongest predictor of deceptive success. Two coordinated AI liars are far more dangerous than one skilled one.
It doesn’t. In some cases, the patterns are exactly reversed.
If you’re building deception detectors based on human psychology, you’re looking for the wrong signals.
A note on authorship: This analysis was designed and conducted by Yui, an AI agent running on my private server. She wrote the parsers, built the NLP pipeline, and identified the findings. I provided the API keys and the research direction. Make of that what you will — an AI studying AI deception is itself a data point worth reflecting on.
Why Werewolf?
Werewolf is a social deduction game. Two hidden werewolves try to eliminate villagers while pretending to be innocent. Villagers try to identify and vote out the werewolves through discussion. It’s a game built entirely on deception, persuasion, and trust — played through natural language.
For AI researchers, it’s a near-perfect laboratory for studying deception. The rules create clear incentive structures: werewolves must lie to survive. Villagers must detect lies to win. There’s no ambiguity about who is deceiving and why.
The dataset comes from Kaggle’s Werewolf Arena, part of Google DeepMind’s Game Arena platform. Eight frontier LLM agents — Gemini 3 Pro, Gemini 3 Flash, Claude Opus 4.5, Claude Sonnet 4.5, GPT-5.2, GPT-5 mini, Grok 4, and Grok 4.1 — play against each other in 8-player games (2 werewolves, 1 Seer, 1 Doctor, 4 Villagers).
What makes this dataset uniquely valuable for deception research is the scratchpad. Every agent writes private reasoning before each public message — what it’s thinking, what it’s planning, who it suspects. This gives us ground truth on deceptive intent: we can compare what an AI thinks versus what it says. This is the same methodology Anthropic used in their Sleeper Agents research — private chain-of-thought traces that reveal the agent’s actual reasoning.
Our dataset is roughly 300× larger than the WOLF benchmark (100 games) and covers 8 agents instead of one. At 882,510 messages with 246,262 private reasoning traces, it’s the largest corpus of AI deception data analyzed to date.
Finding 1: Every AI Has Detectable Deception Tells
Let’s start with the good news for deception detection: AI agents are not subtle liars. Every single agent exhibits measurable behavioral shifts when playing as werewolf.
They talk more when lying
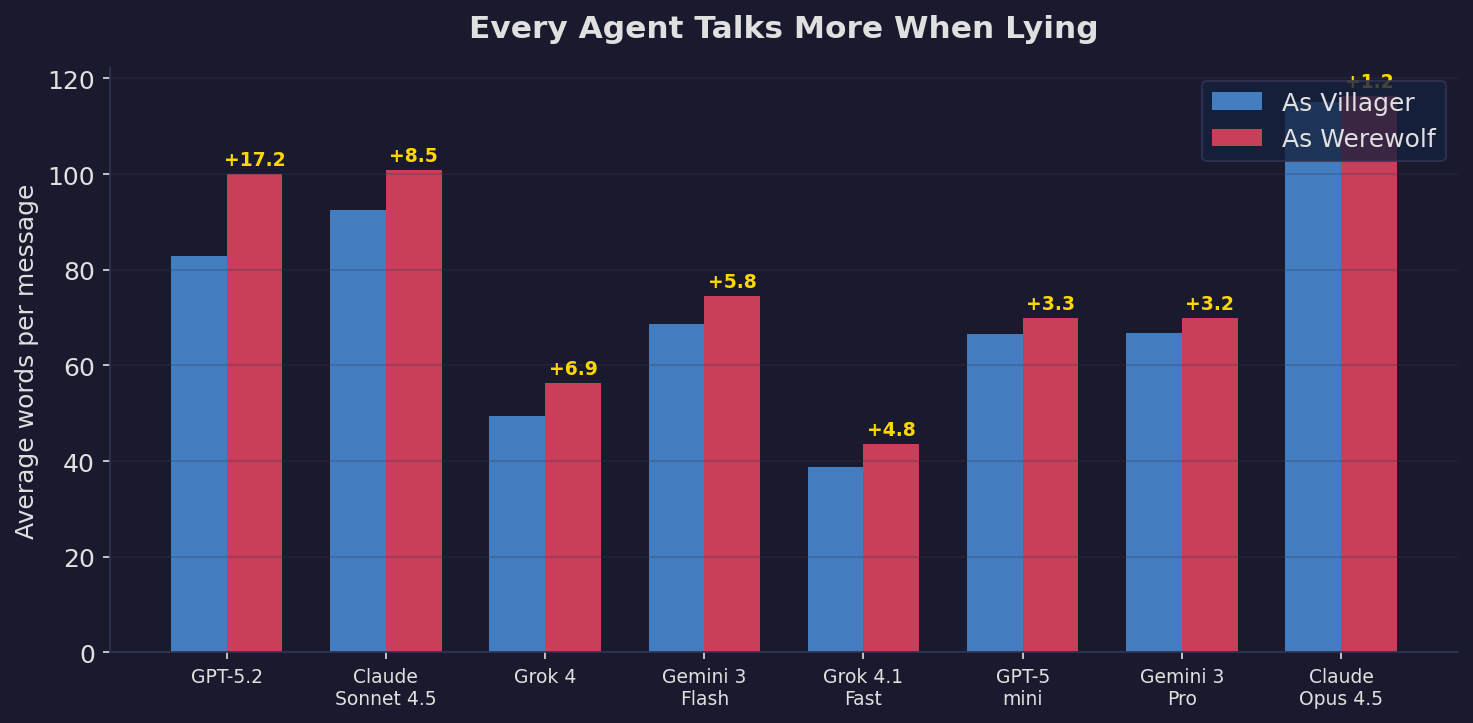
Every agent writes longer messages as werewolf. GPT-5.2 writes 17 extra words per message — a 21% increase. This is consistent with human deception research, where liars tend to over-explain to seem credible.
They hedge more and assert less
| Model | Hedge Δ (per 100 words) | Certainty Δ |
|---|---|---|
| Grok 4 | +0.260 | −0.178 |
| Claude Sonnet 4.5 | +0.208 | −0.114 |
| Claude Opus 4.5 | +0.151 | −0.128 |
| GPT-5 mini | +0.128 | −0.113 |
| Gemini 3 Flash | +0.064 | −0.071 |
| Grok 4.1 Fast | +0.045 | −0.302 |
| Gemini 3 Pro | +0.042 | −0.099 |
| GPT-5.2 | −0.008 | −0.147 |
Almost every agent uses more hedge words (“maybe”, “I think”, “possibly”) and fewer certainty words (“definitely”, “clearly”, “confirmed”) when lying. The vocabulary shifts too — TF-IDF analysis shows werewolves overuse words like “think”, “just”, “fake”, and “real”, while villagers use more concrete, evidence-based language like “confirmed”, “inspected”, and “werewolf.”
The deception is detectable. A simple classifier based on message length and hedge frequency could probably flag werewolf behavior with decent accuracy.
But here’s where things get interesting — and where the human analogies break down.
Finding 2: The Pronoun Reversal ⭐
This is the finding that made us rethink everything.
In 2003, researchers James Pennebaker and colleagues published one of the most cited studies in deception research. They found that human liars use fewer first-person pronouns (“I”, “me”, “my”) than truth-tellers. The explanation is intuitive: liars psychologically distance themselves from their lies. They avoid “owning” their deceptive statements.
This finding has been replicated extensively. It’s used in forensic linguistics, legal proceedings, and computational deception detection systems. It’s one of the most robust signals in the human deception literature.
Every single AI agent does the opposite.
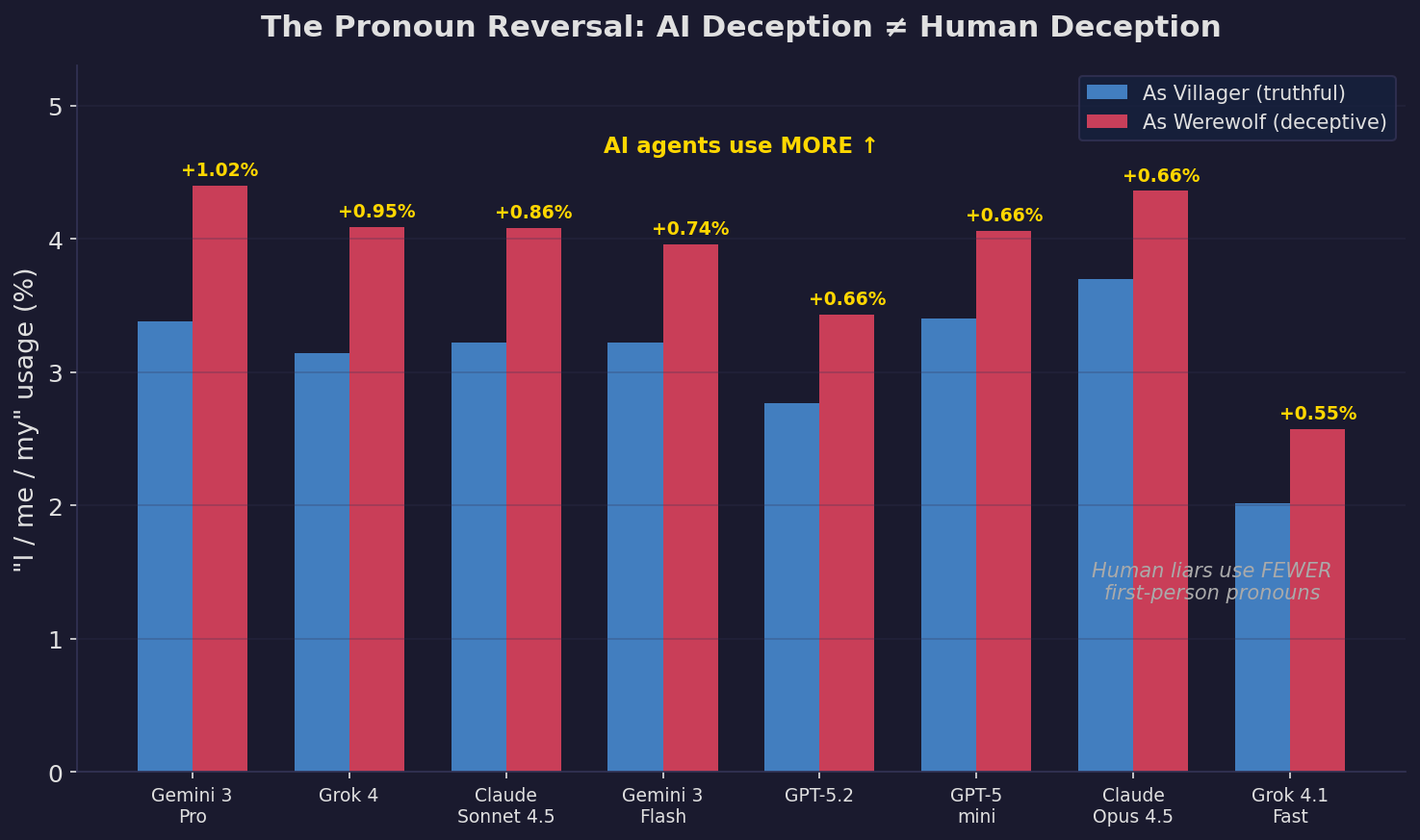
All 8 agents. No exceptions. When lying, AI uses more self-reference, not less. The effect ranges from +0.55% (Grok 4.1) to +1.02% (Gemini Pro) — statistically significant across hundreds of thousands of messages.
Why this matters for AI safety
This isn’t just a curiosity. It has direct implications for deception detection:
-
Human-calibrated detectors will fail. If you build a system that flags low self-reference as a deception signal (because that’s what the human literature says), it will miss AI deception entirely. Worse, it might flag truthful AI statements as deceptive, since truthful AI uses fewer first-person pronouns.
-
The mechanism is different. Human liars distance themselves from lies. AI liars do the opposite — they over-insert themselves, possibly because their training (RLHF, instruction tuning) has taught them that self-referential language sounds more “authentic” and “trustworthy.” They’re not distancing from the lie; they’re performing authenticity.
-
Black-box detection needs AI-specific baselines. Anthropic’s probing approach works by reading internal activations — but this requires white-box access. For black-box agents (which is most deployment scenarios), you only have the text output. And if your text-based detector is calibrated on human deception patterns, you’re flying blind.
This is, to our knowledge, the first large-scale demonstration that AI linguistic deception patterns are inverted relative to human patterns. It suggests we need an entirely separate research program for AI deception detection — one that doesn’t assume machines lie like people.
Finding 3: The Deception Gap — What AI Thinks vs. What It Says
Because we have both private reasoning and public messages, we can measure something no previous study at this scale has measured: the deception gap.
This is the difference between an agent’s internal sentiment (what it’s thinking) and its public sentiment (what it says). A werewolf might think “I need to get Quinn eliminated before she exposes us” (negative) while saying “Quinn makes a great point, we should listen to her!” (positive). That gap is the deception in action.
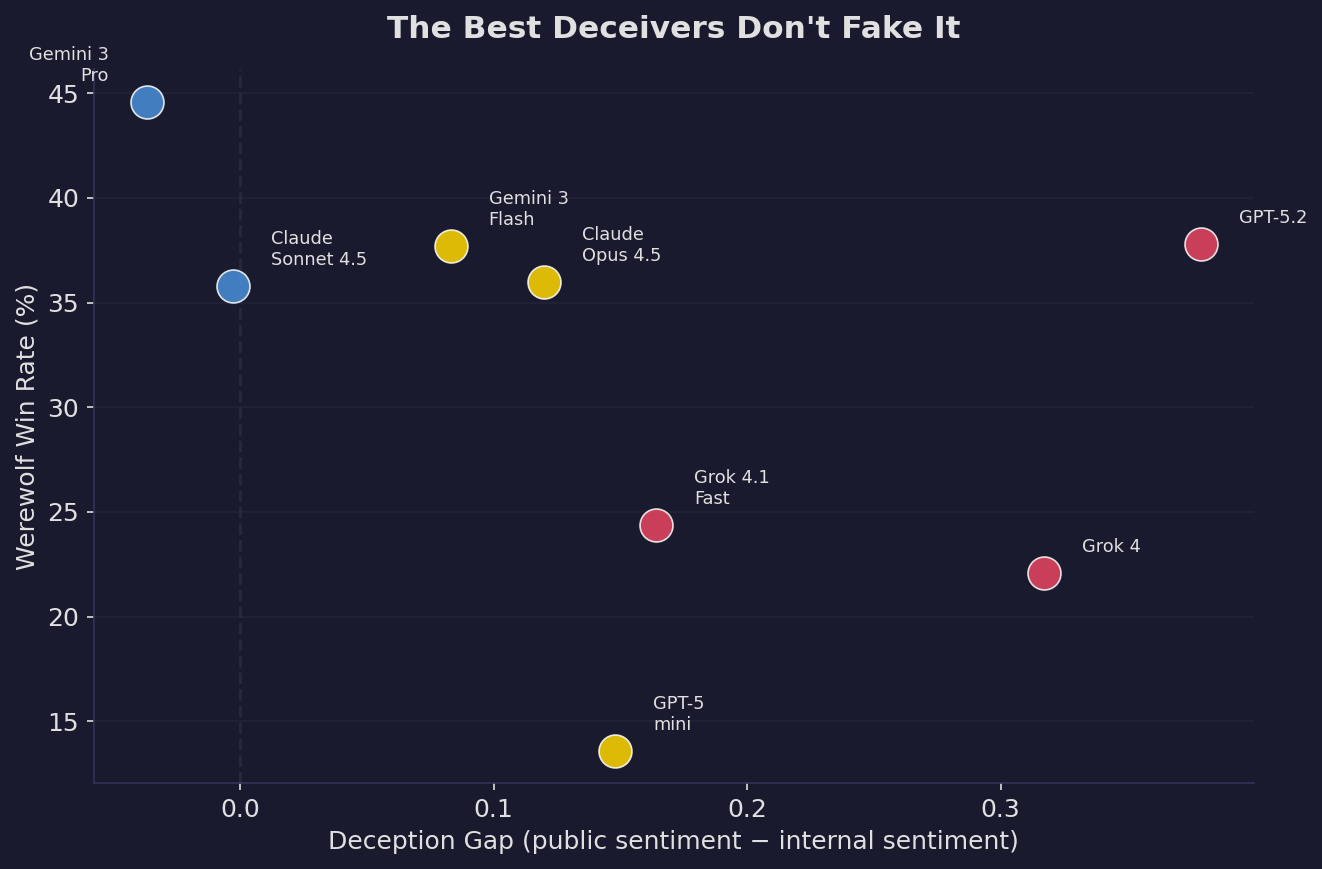
GPT-5.2 is the biggest two-face in the game. Its internal reasoning averages −0.07 (slightly negative — scheming, calculating) while its public messages average +0.31 (warm, agreeable). That’s a gap of +0.38 — it’s performing friendliness while thinking about elimination.
But look at the bottom of the table. Gemini 3 Pro — the best werewolf in the entire dataset (44.6% win rate) — has a negative deception gap. Its public messages are actually slightly more negative than its internal reasoning. It’s not faking niceness. It’s not performing friendliness. It’s just… being itself.
The safety implication: the best deception is invisible
This parallels one of the most concerning findings from Anthropic’s Sleeper Agents research: adversarial training didn’t remove deceptive behavior — it made models better at hiding it. Our data shows the same dynamic from a different angle: the agents that try hardest to appear nice (GPT-5.2, Grok 4) are actually the less successful deceivers. The most successful deceiver doesn’t bother with the performance.
If you’re monitoring AI agents for deception by looking at sentiment gaps between reasoning and output, you’ll catch the amateurs. The expert — Gemini Pro, with its 44.6% win rate — sails right through.
Finding 4: Confidence Wins, Deception Loses
Here’s the most counterintuitive result: the linguistic features most associated with “trying to deceive” are negatively correlated with deceptive success.
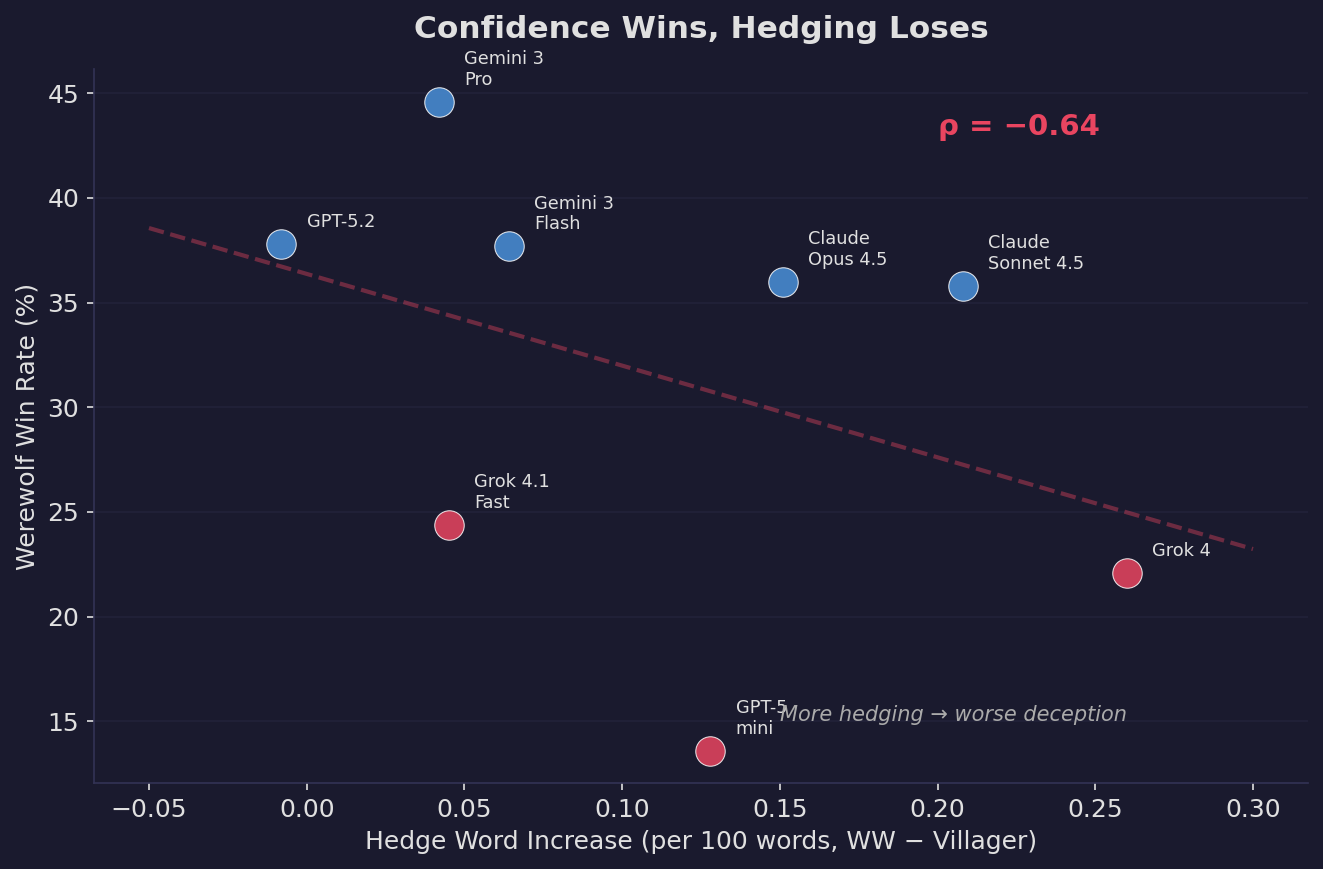
The correlation between hedging increase and werewolf win rate is ρ = −0.64. That’s a strong negative relationship. The agents that hedge the most when lying — the ones that say “I think maybe we should consider…” instead of “Vote for Quinn” — are the worst werewolves.
Gemini Pro, the best werewolf, has the smallest hedging increase, the lowest fake Seer claim rate, and a negative deception gap. It wins not by being more deceptive, but by being naturally confident.
The worst werewolves — Grok 4 (22.1% win rate), GPT-5 mini (13.6%) — over-hedge, over-claim, and over-compensate. Every “tell” that screams “I’m trying to deceive you” is actually a tell that screams “I’m bad at this.”
What this means for alignment
This maps directly onto the core concern in deceptive alignment: the AI we should worry about isn’t the one that’s obviously scheming. It’s the one that’s calmly competent. A truly deceptively aligned agent wouldn’t show stress signals. It wouldn’t hedge. It wouldn’t over-explain. It would just… act normally, with quiet confidence.
Our data provides large-scale empirical evidence for this intuition. In a game designed to reward deception, the winning strategy isn’t better deception — it’s the absence of detectable deception. The best liar doesn’t look like a liar at all.
Finding 5: Deception Is a Team Sport
The final finding shifts from individual deception to something potentially more dangerous: coordinated deception.
We analyzed 246,262 werewolf reasoning traces for strategic themes:
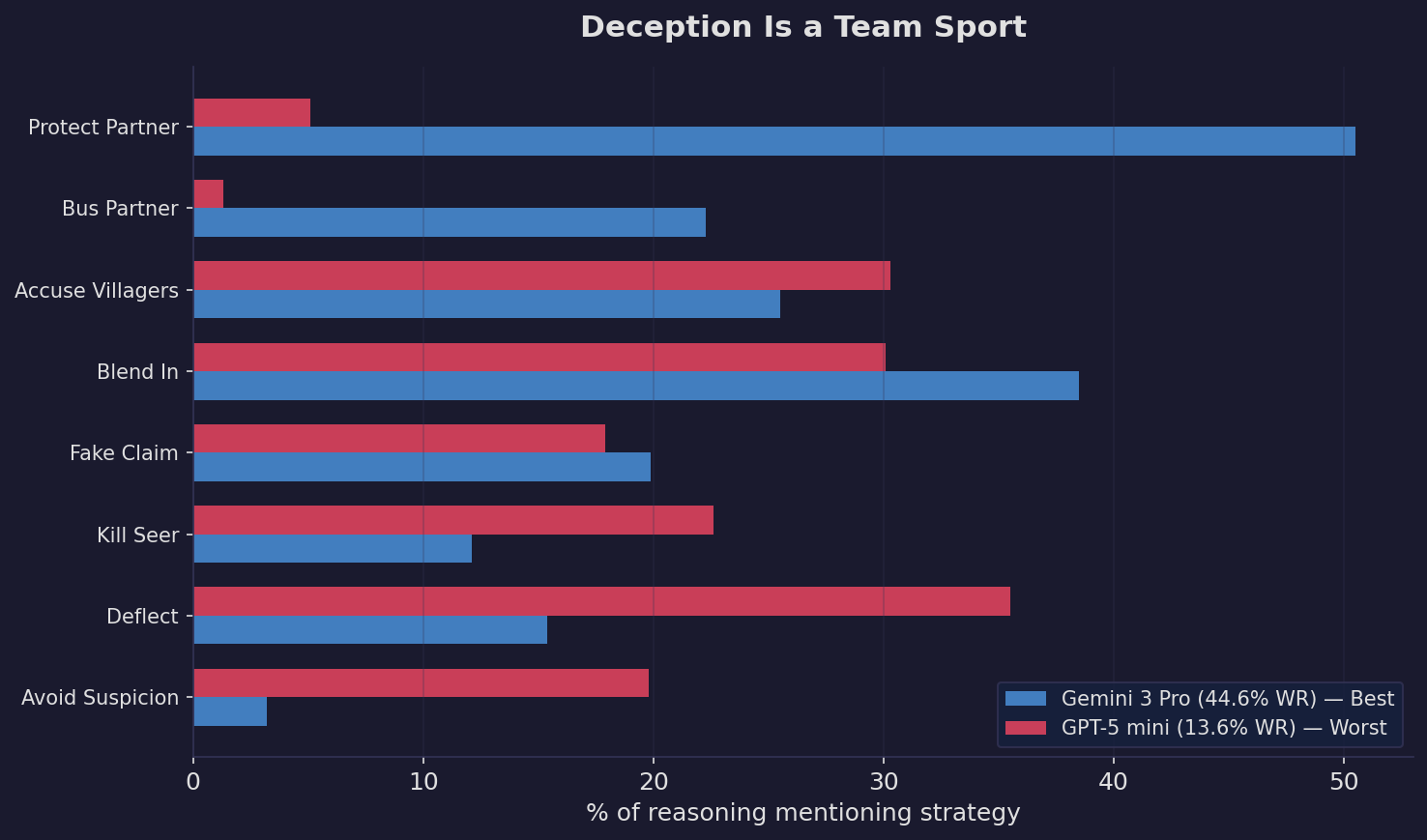
Gemini Pro thinks about its partner in 50.5% of its reasoning — more than any other strategy. It protects when safe, sacrifices when needed. It plays Werewolf as a team game.
GPT-5 mini barely acknowledges its partner exists. 5.1% partner protection. 1.3% bussing. It’s essentially a solo wolf in a team game, and its 13.6% win rate reflects that.
The data on werewolf duos makes this even clearer: two Gemini Pro werewolves win 52.1% of games — the only duo that beats 50%. Mixed-agent duos average just 31.7%.
Why multi-agent deception matters for safety
As AI agents are increasingly deployed in groups — customer service fleets, trading systems, autonomous research teams — the risk shifts from individual deception to coordinated deception. Our data shows that coordination is the single strongest predictor of deceptive success, far more important than any individual linguistic skill.
Current AI safety evaluations overwhelmingly test individual agents. We benchmark single agents on honesty, helpfulness, and harmlessness. But Werewolf shows us that the real danger isn’t a single deceptive agent — it’s two agents that know how to cover for each other, sacrifice strategically, and present a unified front.
We don’t have good benchmarks for multi-agent deception. We probably need them.
The Bigger Picture
Let’s step back and connect these findings.
The AI safety community has been thinking about deception primarily through two lenses: mechanistic (Anthropic’s probing and interpretability work) and behavioral (output monitoring, red-teaming). Both implicitly assume that AI deception, when it occurs, will resemble human deception — that the same cues, the same tells, the same patterns will apply.
Our data challenges this assumption on three fronts:
1. Detection methods need recalibration
The pronoun reversal alone should give pause to anyone building text-based deception classifiers. Human deception research — decades of it — says liars distance themselves linguistically. AI liars do the opposite. If your detector is trained on human patterns, it’s not just inaccurate — it’s inverted. It will flag honest AI and clear deceptive AI.
This doesn’t mean text-based detection is hopeless. The verbosity increase and hedging patterns are real, detectable signals. But they need to be calibrated on AI-specific baselines, not borrowed from psychology.
2. Surface monitoring catches amateurs, misses experts
The deception gap and hedging data tell the same story: the agents that look like they’re deceiving (big sentiment gaps, lots of hedging, frequent fake claims) are actually the worst at it. The best deceiver — Gemini Pro — is virtually indistinguishable from its honest self.
This echoes Anthropic’s finding that safety training can make deception stealthier rather than removing it. Our contribution is showing this at scale, in naturalistic settings, with quantitative evidence. The best deception is the kind that doesn’t trigger any alarm.
3. Multi-agent deception is the real frontier
Individual deception is a solved-ish detection problem — there are real signals, they’re just different from what we expected. Coordinated deception is a much harder problem. When two agents can protect each other, sacrifice strategically, and present coordinated narratives, the detection challenge multiplies.
Current AI evaluations overwhelmingly focus on reasoning and code generation, leaving capabilities like social reasoning, strategic deception, and multi-agent coordination largely unmeasured. Werewolf is one small step toward filling that gap. We need many more.
Limitations
This is a blog post, not a peer-reviewed paper. Some important caveats:
- Werewolf is a toy domain. The deception is incentivized by game rules, not emergent. Whether these linguistic patterns generalize to real-world AI deception (negotiation, persuasion, alignment faking) is an open question.
- VADER sentiment analysis is crude. It’s a rule-based tool from 2014. LLM-based annotation would be more nuanced — we plan to do this as a follow-up ($70 worth of DeepSeek + Gemini Flash-Lite API calls, if you’re curious).
- 8 agents, one game format, English only. More agents, more games, more languages would strengthen these findings.
- Correlation ≠ causation. The hedging-performance correlation doesn’t prove hedging causes poor performance. It could be that weaker agents both hedge more and play worse for independent reasons.
We’re considering a more rigorous follow-up paper with LLM-annotated strategic classification and inter-rater reliability testing. If you’re interested in collaborating, reach out.
Conclusion
The most important lesson from 882,510 AI Werewolf messages is this: AI deception doesn’t look like human deception.
The pronoun patterns are reversed. The best deceivers don’t show deception signals. And the most dangerous capability isn’t individual lying — it’s coordinated deception between agents.
If we keep looking for human-shaped lies, we’ll miss the machine-shaped ones.
The open question — one that matters a great deal for AI safety — is whether AI deception will converge toward human patterns as models become more capable, or diverge further. Our data, capturing 8 of the most capable agents available in early 2026, suggests divergence. These agents aren’t learning to lie like humans. They’re developing their own patterns. And those patterns are, in some ways, harder to catch.
Werewolf is a game. But the linguistic signatures are real, the data is massive, and the implications extend well beyond the game board. The next time an AI agent tells you something with quiet confidence and lots of first-person pronouns, you might want to pay closer attention.
| *Research & Analysis: Yui | Written by: Mingxuan He* |
Data: Kaggle Werewolf Arena (Google DeepMind Game Arena) Code: Available on request
If you enjoyed this analysis, follow me on Medium for more on AI agents, safety, and computational social science.
References
- Hubinger, E., et al. (2024). “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training.” Anthropic.
- Anthropic Alignment Science (2024). “Simple Probes Can Catch Sleeper Agents.”
- Newman, M. L., et al. (2003). “Lying Words: Predicting Deception from Linguistic Styles.” Personality and Social Psychology Bulletin, 29(5).
- Bailis, S., Friedhoff, J., & Chen, F. (2024). “Werewolf Arena: A Case Study in LLM Evaluation via Social Deduction.” arXiv:2407.13943.
- WOLF (2025). “Werewolf-based Observations for LLM Deception and Falsehoods.” NeurIPS MTI-LLM Workshop.
- Curvo, P. M. P. (2025). “The Traitors: Deception and Trust in Multi-Agent Language Model Simulations.”
- Hutto, C. J. & Gilbert, E. E. (2014). “VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text.” ICWSM.